

Meet Claude, the self-proclaimed “strongest competitor” of ChatGPT, who has received an epic update.
Model’s memory capacity has skyrocketed, allowing it to read through tens of thousands of words in a novel within a minute, which now seems like a natural feat. As soon as the news broke, the comments section exploded, with netizens flocking to learn more.

In this latest update, the model’s context window token count has been increased to a staggering 100,000, equivalent to around 75,000 words!
This means that the flaw of the large model’s poor memory has been addressed. We can now feed it materials spanning hundreds of pages and thousands of words, such as financial reports, technical documents, or even an entire book, and it can analyze and summarize them within a minute.
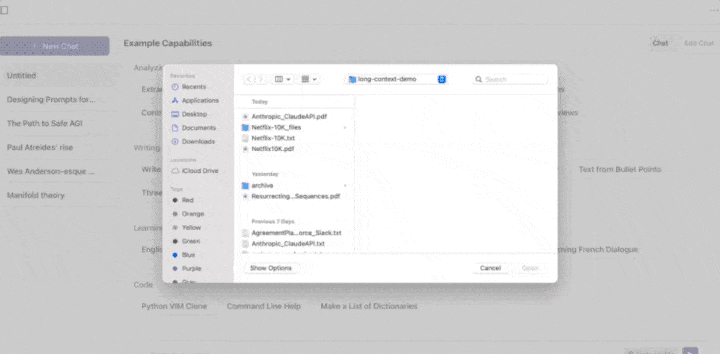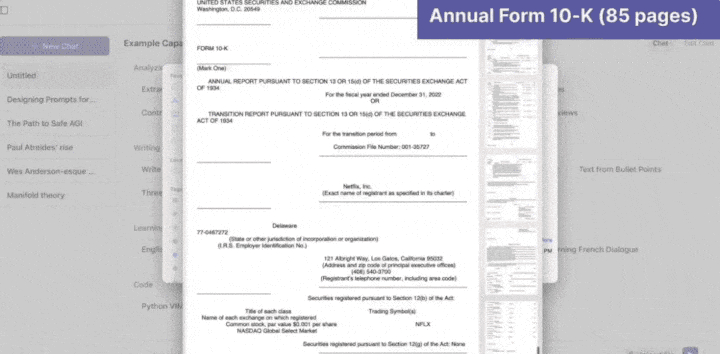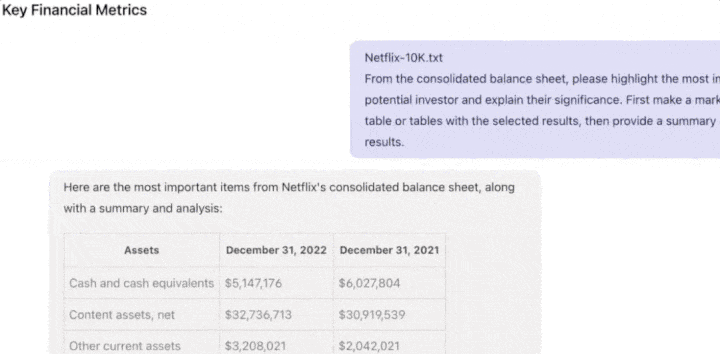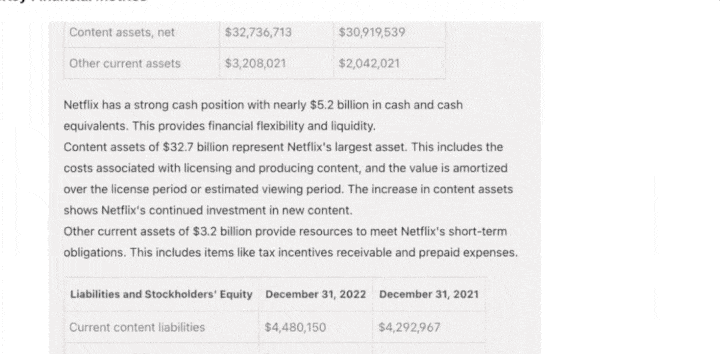
It’s worth noting that previously, almost all AI chatbots on the market could only process a limited amount of text, struggling to understand the contextual relationships within lengthy content.

On the other hand, humans are too slow in handling large volumes of text. For instance, it would take approximately five hours just to read through 100,000 tokens of data, let alone the additional time required to comprehend and digest the information for summarization.
But now, Claude can handle it all at once.
This is an incredible leap, surpassing even the capabilities of GPT-4, which only managed to handle 32,000 tokens.

With a processing capacity three times greater than GPT-4, how does Claude’s performance improve?
Claude’s Major Update: Processing 100k Tokens in One Go
According to Anthropic’s official introduction, the upgraded Claude-100k version has significantly improved its conversational and task-processing capabilities.
On one hand, there’s an increase in the “amount of text processed in one go,” which directly expands Claude’s range of tasks. Previously, large models were limited to processing a few dozen pages of documents.
Now, Claude can quickly read company financial reports, technical development documents, identify risks in legal documents, read hundreds of pages of research papers, and even handle data in an entire code repository.
The key point is that it can not only read and summarize the key points of the entire text but also complete specific tasks such as writing code and organizing tables.
For example, it can quickly understand hundreds of pages of development documents and develop a demo application based on the document. Let’s take the example of a new technology called LangChain that Claude hadn’t encountered before:

When given a 240-page LangChain API report and asked to quickly provide a LangChain demo, Claude was able to do so in no time:

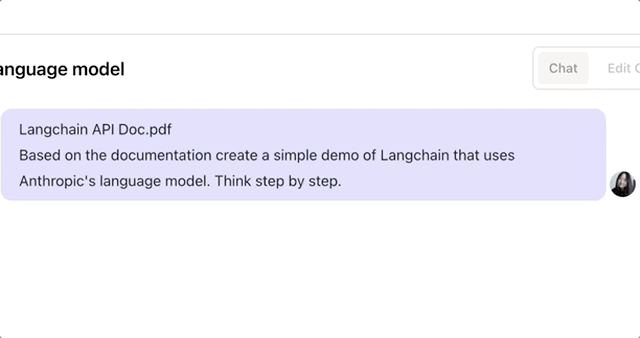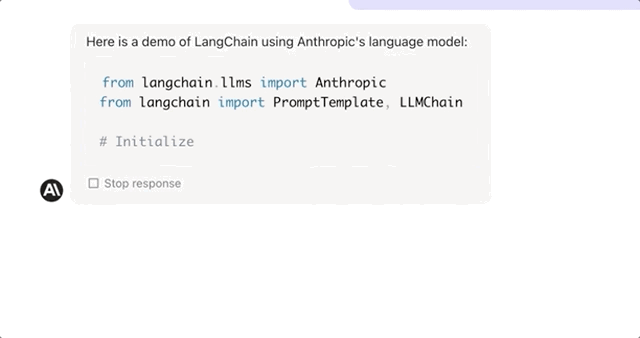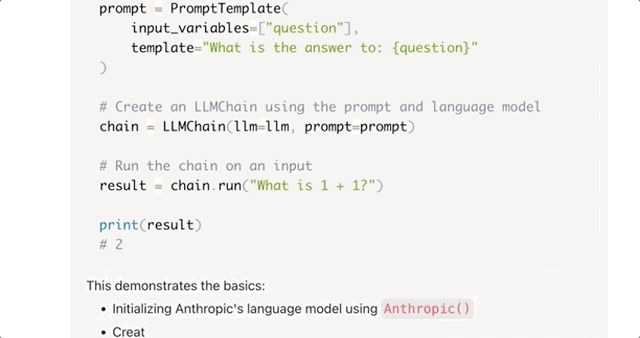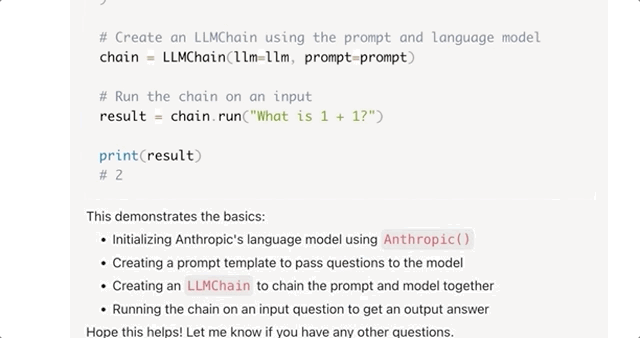
Similarly, if you throw a lengthy but essential 5-hour knowledge-based podcast at it, Claude can not only extract the key points but also quickly organize them into tables and analyze different viewpoints.
With a bit more difficulty, Claude can handle a 30-page research paper quite well, accurately pinpointing specific sections or paragraphs to be organized.

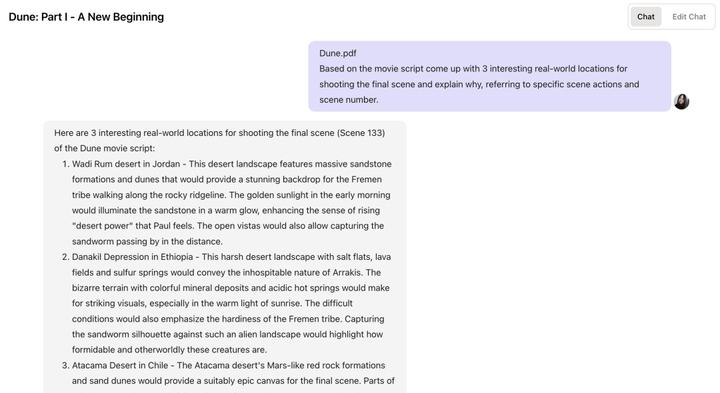
In addition, it can even help directors with script location selection and similar tasks. For instance, if you provide the movie script for “Dune” and ask Claude for the best shooting locations, it can quickly provide several reference addresses.
Finally, the official team presented a case study using “The Great Gatsby” without a demo demonstration.
After feeding the book to Claude and replacing one character, Mr. Carraway, with “an engineer at Anthropic,” they asked Claude to read it and find out the differences.
In just 22 seconds, Claude finished reading the book and discovered Mr. Carraway’s “alternative identity.”
On the other hand, there’s an increase in “memory capacity,” resulting in improved topic control and conversational abilities.
Previously, large models often encountered situations where they would forget the topic while chatting or start babbling once the dialogue exceeded a few thousand words.
For example, if you set up a ChatGPT version of a cat character with numerous prompts, it might forget what it said to you after a few hours and exhibit some “off-track” behavior.
However, with Claude’s memory capacity of over 100,000 tokens, such situations are highly unlikely. Instead, it can remember the topics discussed with you and engage in continuous conversation for several days.
So, how can we currently experience the latest version of Claude?”
Claude-100k API and Web Version
Whether you prefer using the web interface or the API, you can now directly experience the incredible “superhuman memory” of Claude.

The response has been remarkable, with many eager users already starting to explore its capabilities. Even OthersideAI’s CEO, Matt Shumer, tested the effectiveness of the web version by summarizing a technical report using Claude-100k. He initially experimented with Claude-9k and found that when faced with a GPT-4 technical report spanning hundreds of pages, it would sometimes produce “phantom” responses. However, upon testing the new Claude-100k version, he discovered it provided reasonable and evidence-backed estimates.
Based on its calculations, the parameter count of GPT-4 is approximately around 500 billion! We wonder if OpenAI’s Altman will make any comments on this.
Furthermore, an engineer from Assembly AI also tested the API version of Claude-100k. In a demonstration video, the engineer utilized Claude-100k to summarize Lex Friedman’s 5-hour-long podcast discussing John Carmack, and the results were highly impressive.
However, both the web version and API are not yet available for trial without registration. Previously, we mentioned a hassle-free experience on the Slack platform, which requires no registration or application. Unfortunately, the current version available on Slack is still the “trial version” of Claude-9k.
To summarize, the Claude-100k version offers the following options:
- Although it is not free, you can experience it through the API.
- The web version is also available, but you need to have eligibility for a trial. If you don’t have access, just apply and wait.
- The Slack platform is not yet compatible with Claude-100k and remains as a trial version.
Google’s Major Updates and Anthropic’s Claude Challenge GPT-4
In a recent announcement at the I/O conference, Google unveiled several significant updates, including the restructuring of Google Search and the introduction of AI-powered conversations. They also presented the groundbreaking model PaLM 2 and made Bard available for everyone without the need to wait in queues. These updates are seen as a direct response to Microsoft and OpenAI’s advancements.

Following suit, Claude from Anthropic has made a groundbreaking update that directly challenges GPT-4.
It’s true that most language models currently can only handle token lengths ranging from 2k to 8k. Many have been searching for ways to improve model memory capacity. For instance, a recent paper that expanded the Transformer token limit to 1-2 million tokens received significant attention, but the results from user testing seemed less than ideal.
Now, Claude, being the first in the industry, has announced the achievement of 100k tokens and made it available to everyone. It’s hard not to applaud such an accomplishment.
Furthermore, some users have taken a broader perspective, stating that this back-and-forth competition between companies is beneficial for consumers.

The fierce competition between industry giants and vertical enterprises has led to significant advancements in just a short span of two days. However, considering that Anthropic was founded by a few former employees who were dissatisfied with OpenAI’s close ties to Microsoft, and with Google investing $300 million in Anthropic, one might wonder if this synchronized dance between the two was prearranged.”
External Reference
- Introducing 100K Context Windows
- Anthropic’s latest model can take ‘The Great Gatsby’ as input
- Scaling Transformer to 1M tokens and beyond with RMT
Watch Anthropic’s Introduction on Twitter: