

For years, the inner workings of AI models have remained inscrutable, resembling black boxes that generate predictions without clear explanations. This lack of transparency has been a major hurdle in gaining human trust and comprehending the decision-making processes of AI systems. OpenAI’s research aims to address this by developing techniques that enable AI to explain its own reasoning in a way that humans can understand.
Humans themselves mostly explain their behavior with lies, fabrications, illusions, false memories, and post-hoc reasoning, just like AI
anonymous netizen comment
Employed GPT-4 to Explain the Behavior of GPT-2
In the era where new products are constantly emerging and AI is reshaping the face of business civilization, there’s still so much we don’t know about the inner workings of these astonishing technologies.
AI understands AI, and soon enough, AI trains AI, and in a few more years, AI creates new AI
anonymous netizen comment
AI, the language model, is a black box that remains beyond human comprehension. We are left clueless about how to even begin studying it to gain understanding.
Read More

But what if the one studying this black box is not a human, but AI itself?
It’s a curious yet highly dangerous idea. Because we can’t even fathom the extent to which the results of such research could overturn our understanding of the human brain and AI that has been established for years.
However, someone has dared to venture into this territory. Just few days ago, OpenAI released their latest research findings, where they employed GPT-4 to explain the behavior of GPT-2, and the preliminary results are astounding.
To put it mildly, people are utterly astonished, pleading, “Please keep it far away from awakening”
“AI understands AI, and soon enough, AI trains AI, and in a few more years, AI creates new AI.”
But from an objective standpoint, the academic community is brimming with excitement, exclaiming, “OpenAI has just solved the problem of interpretability“.
GPT-4: Bridging the Gap Between Humans and Machines
OpenAI has made a groundbreaking discovery in this field. In their latest blog post, titled “Language Models Can Explain Neurons in Language Models,” they introduce a tool that leverages GPT-4 to analyze the behavior of neurons in simpler language models, specifically focusing on GPT-2, an open-source large-scale model released four years ago.
Similar to the human brain, large language models (LLMs) are composed of “neurons” that observe specific patterns in the text and influence the generated output. Let’s take an example: suppose there is a neuron dedicated to “Marvel superheroes.” When a user asks the model, “Which superhero has the strongest abilities?” this neuron will increase the probability of the model mentioning Marvel heroes in its response.
OpenAI’s developed tool utilizes this principle to establish an evaluation process. Before diving into the evaluation, GPT-2 runs a sequence of text, waiting for a particular neuron to be frequently “activated.”
The evaluation process consists of three steps:
- Analyzing the text and activation patterns. When GPT-4 is given some text, it generates coherent explanations that are highly relevant and accurate. For instance, when given Marvel-related text, it can identify keywords related to movies, characters, and entertainment.

- Simulating GPT-2’s Neural Activities. GPT-4 then simulate and predict the next actions of GPT-2’s neural network with astounding accuracy.
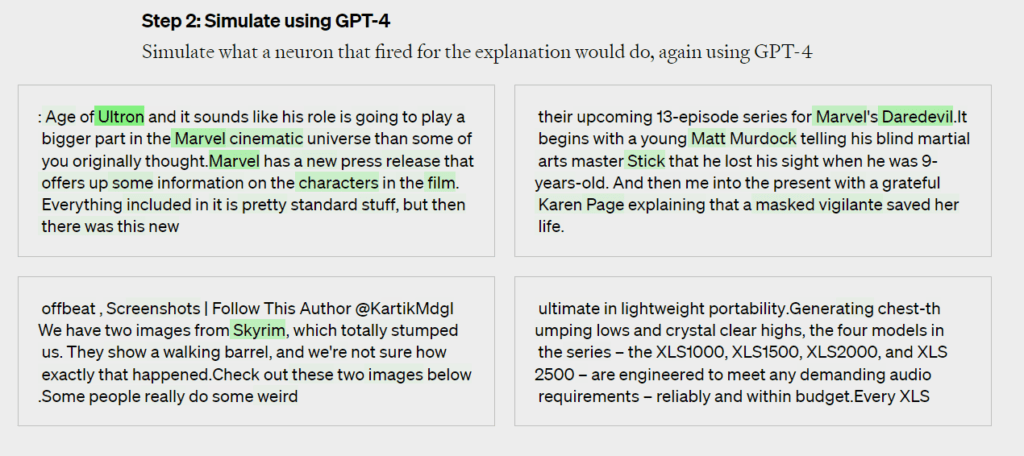
- Finally, comparing the 2 results and assessing the scores. By comparing the results generated by the GPT-4 simulated neurons with those produced by the GPT-2 real neurons, we can determine how accurate GPT-4’s predictions are.
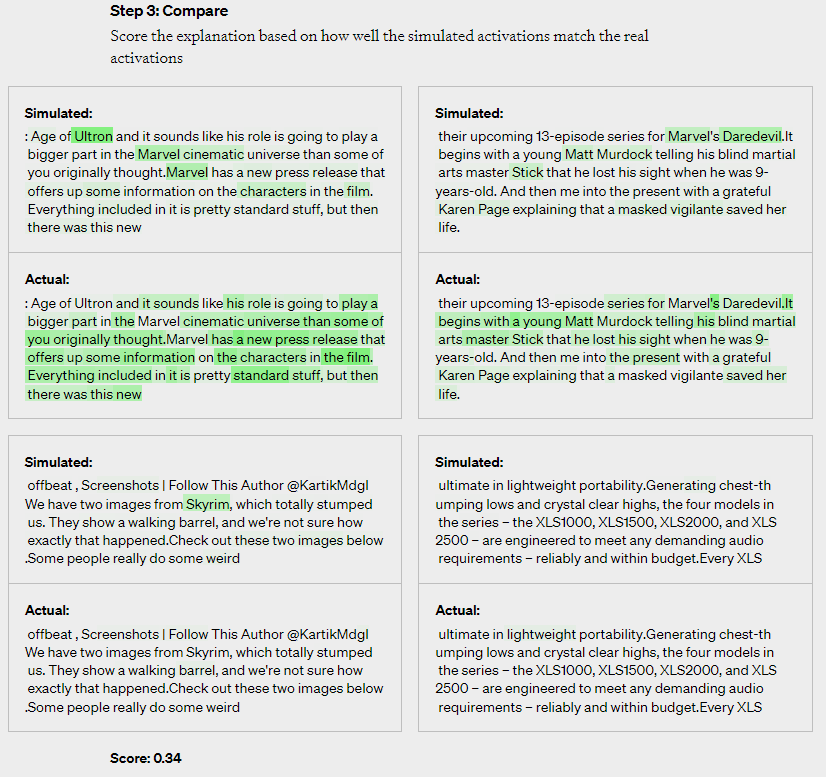
In understanding the behavior of each neuron in their GPT-2 neural network by providing natural language explanations and evaluating the degree of alignment of their correspondence to actual behavior with scores. They successfully explained all 307,200 neurons in the GPT-2 network, compiled the explanations into a dataset, and released it on GitHub alongside the tool code.
LLM – The Alien Feature: Machines Beyond Human Comprehension
The imperfections in the explanations generated by GPT-4, particularly when it comes to explaining larger models compared to GPT-2. The performance in explaining these larger models has been subpar, possibly due to the increased difficulty in interpreting those later layers.
Evaluation of GPT-2 Explanations
The evaluation of GPT-2 explanations has mostly resulted in low scores, with only around 1000 explanations receiving higher ratings (above 0.8).
Challenges in Explanation Generation
Jeff Wu from OpenAI’s Scalable Alignment team highlighted that many explanations have low scores or fail to explain the behavior of actual neurons comprehensively. Some neurons exhibit activation patterns that are difficult to discern, remaining active in five or six different aspects without any distinguishable pattern. At times, there are clear patterns that GPT-4 fails to identify.
OpenAI’s Confidence and Proposed Solutions
Despite the current shortcomings, OpenAI remains confident and believes that they can enhance GPT-4’s ability to generate explanations using machine learning techniques. They propose several approaches, such as repeatedly generating explanations and modifying them based on activation patterns, employing larger models for explanation generation, and adjusting the structure of the explanation model.
Limitations of the Current Approach
OpenAI acknowledges that the current methodology has its limitations. The use of concise natural language for explanations may not capture the complexity of neuron behavior and might not provide a succinct description. Neurons may possess multiple distinct concepts or even concepts that lack linguistic description or human comprehension.
Future Goals: Automated Explanation of Complex Behavior
OpenAI’s ultimate objective is to automate the discovery and explanation of entire neural circuits responsible for complex behaviors. However, the current methods only explain the behavior of individual neurons without considering downstream effects.
Explaining Behavior without Mechanism
While explaining neuron behavior is essential, OpenAI recognizes that it falls short of explaining the mechanisms underlying such behavior. This means that even high-scoring explanations can only describe correlations without uncovering causation.
Alien Features and Unexpressed Concepts
OpenAI suggests that language models may represent unfamiliar concepts that humans cannot express in words. This could be because language models focus on different aspects, such as statistical structures for predicting the next token or discovering natural abstractions that humans have yet to explore, like concept families across different domains.
Language models may represent alien concepts that humans don’t have words for. This could happen because language models care about different things, e.g. statistical constructs useful for next-token prediction tasks, or because the model has discovered natural abstractions that humans have yet to discover, e.g. some family of analogous concepts in disparate domains.
Language models can explain neurons in language models – OPENAI
GPT-4 in AI Alignment Research
However, OpenAI is taking a significant step forward by developing methods to predict potential issues with AI systems. William Saunders, the Head of OpenAI’s Explainability team, recently stated, “We aim to truly achieve trustworthiness in the behavior and responses generated by these models“.
Sam Altman also shared a blog post highlighting GPT-4’s breakthrough in enhancing explainability compared to its predecessor, GPT-2.
Explainability, a subfield of machine learning, focuses on gaining a clear understanding of a model’s behavior and interpreting its results. In simple terms, it aims to answer the question, “How does the machine learning model achieve its outcomes?”
Since 2019, Explainability has become a vital area of research in machine learning. It helps developers optimize and adjust models. If we consider AI as a black box, without understanding how it makes decisions, it cannot fully resolve the trust issues among certain individuals, even if it performs flawlessly in various scenarios.
Without understanding how it makes decisions, it cannot fully resolve the trust issues among certain individuals, even if it performs flawlessly
anonymous netizen comment
OpenAI’s use of GPT-4 to address explainability is an attempt to automate AI research. It aligns with their overall strategy of automating alignment research, as stated by William Saunders, “This is part of our third pillar of alignment research: automating alignment. We hope that this direction will keep pace with the development of AI.”
In the summer of 2022, OpenAI published an article titled “Our Approach to Alignment Research,” outlining their research strategy.
According to the article, OpenAI’s alignment research is supported by three pillars:
- Training AI using human feedback
- Training AI systems to assist human evaluation
- Training AI systems for alignment research
“Language models are particularly suited for automating alignment research because they are ‘pre-loaded’ with vast knowledge and information about human values through their exposure to the internet. They are not independent agents and therefore do not pursue their own goals”.
Discussions Flooded OpenAI’s Tweet
While the intention of OpenAI is commendable, the results of the study have caused widespread concern among netizens.
Many social media users responded to OpenAI’s tweet with memes, urging the company to slow down. Some commenters expressed their skepticism about the usefulness of a language model that explains concepts that are already difficult to comprehend.
One commenter said, “You have removed the guardrail,” while another said, “It is fascinating, but it also makes me extremely uncomfortable.”
Some netizens also raised deeper concerns about the implications of creating a language model that can explain its own thinking processes. One commenter wondered how many new words we would need to describe the concepts discovered by AI, while another questioned whether these concepts would be meaningful or teach us anything about ourselves.
Another netizen responded, “Humans themselves mostly explain their behavior with lies, fabrications, illusions, false memories, and post-hoc reasoning, just like AI.”
The concerns raised by netizens are not unfounded. As AI continues to advance at an unprecedented pace, it is important for researchers and developers to consider the ethical implications of their work and ensure that the benefits of AI are shared by all.